Load balancing is a key component of a Data Center application that facilitates high availability and scalability of your application. Data Center does not include a load balancing solution, so you will need to select and configure one that best fits your environment. This article explains some of your options when using a load balancer for a Data Center application.
Technology overview
Since the distinction between load balancers and proxy servers can be confusing, here is a brief overview of the different technologies.
Load balancer
A load balancer distributes incoming user requests across your cluster to minimize response time and avoid overloading any single node. The load balancer also returns the response from the selected server to the user. For Data Center applications, the load balancer serves three essential functions:
- Distributes traffic efficiently across multiple nodes
- Ensures high availability by sending traffic only to nodes that are online (requires health check monitoring)
- Enables the ability to add and remove nodes
For information on using the load balancer in distributing traffic based on traffic type, see Traffic distribution with Atlassian Data Center.
Reverse proxy
A reverse proxy is an intermediary server that prevents direct non-internal network access to your backend servers. It accepts user requests, forwards those to your application servers for processing, and then returns the server response to the user. Reverse proxies also provide caching, which can potentially improve performance by automatically returning common or duplicate server responses.
You can use a single component, such as Nginx, as both a load balancer and a reverse proxy. You can also use different components for each function, such as using Nginx as a reverse proxy, and HAProxy as a load balancer. You will need to consult the product documentation to decide which configuration best fits your environment.
Forward proxy
A forward proxy, or outbound proxy, allows a server on your internal network to access a public hosted server operating outside of your network. For example, an Atlassian application can access the Atlassian Marketplace through a forward proxy.
Balancing algorithms
A load balancer distributes traffic to a specific node in the cluster based on which algorithm you select or configure. Data Center applications don't require a specific type of balancing algorithm; however, Data Center applications use sticky sessions, as explained below. This means that once a new user session has started, each subsequent request in that session goes to the same node within the Data Center cluster. You should test the application before deploying to production, and ensure that the chosen algorithm works as expected in your environment.
Here are three popular load balancing algorithms.
Round robin
The load balancer sends each new session to the next node in the cluster from the last request. Therefore, if the previous request went to Node 1, the next request goes to Node 2. After the load balancer sends a new session to all nodes in the cluster, it starts over with Node 1. Round robin is the most widely used and easily implemented balancing algorithm.
Least connections
The load balancer sends each new session to the node in the cluster that has the least number of existing connections. While this algorithm may better balance the load when a new node joins the cluster, you should take precautions to prevent the immediate overload of the new node.
IP hash
The load balancer calculates a hash value based on the client's IP address, and then uses that hash value to assign a node to the new session. This algorithm ensures that requests from the same IP address go to the same node as long as it is available.
Configuration
Types of load balancers
Data Center supports both hardware- and software-based load balancers. Software load balancers should run on dedicated machines. For both software and hardware solutions, the load balancer should be connected to the application cluster using a high-speed LAN connection to ensure high bandwidth and low latency.
Popular software load balancers include HAProxy, Apache, and Nginx.
Popular hardware load balancer vendors include F5, Citrix, Cisco, VMWare, and Brocade.
Sticky sessions
As mentioned above, Data Center applications assume that each user's request will go to the same node during a session. If requests go to different nodes, users may be unexpectedly logged out, and may lose information stored in their session. Therefore, it is required to bind a session to the same node by enabling cookie-based "sticky sessions" (or session affinity) on the load balancer. When using cookie-based sticky sessions, you can use the cookie issued by the Atlassian application, or you can use a cookie generated by the load balancer. Most Atlassian applications issue the JSESSIONID cookie. Bitbucket versions 5 and later issue BITBUCKETSESSIONID by default. Check the product documentation to verify which cookie the product uses.
For more information on JSESSIONID and cookie-based sticky sessions, see Jira Data Center load balancer examples.
Administrative access
However your load balancer is configured, ensure that you have administrative access to each node behind the load balancer. This access is mainly for maintenance purposes. For example, if you need to rebuild the Jira index on a node, you may need to access it directly to take it out of the cluster, and then add it back to the cluster after the process is complete.
Health check status
The load balancer should be configured to frequently monitor the status of each node, and ensure that it is sending traffic to normally operating nodes. You can check the status of the node by checking HTTP://<node_IP_address>:<port>/status. The node will respond with an HTTP response and a JSON payload describing the state of the node. The load balancer can use either response for determining where to send live traffic. For example, response codes for Confluence are:
| HTTP Response | JSON Response | Action |
|---|---|---|
| 200 | {"state":"RUNNING"} | The node is operating normally. Ok to send live traffic. |
| 503 |
{"state":"STARTING"} |
The node is starting. Do not send live traffic. |
| 503 |
{"state":"STOPPING"} |
The node is stopping. Do not send live traffic. |
| 500 | {"state":"ERROR"} | The node is in an error state. Do not send live traffic. |
| 200 | {"state":"FIRST_RUN"} | The node is being configured for the first time. Do not send live traffic. |
You will need to use a custom health check script on the AWS Elastic Load Balancer with versions of Jira 7.2.9 and earlier, as these return an HTTP response of 200 for every non-error state, and the AWS Elastic Load Balancer only checks HTTP response.
Node removal
The load balancer should allow for a "graceful" shutdown of your nodes when removing them for maintenance purposes. This setting stops the load balancer from sending the node new connections, but keeps current ones active until they end on their own. For example, HAProxy does this when a node is set to either "drain" mode or set to a weight of 0. After all sessions have ended, you can then remove the node from the cluster. If you remove a node abruptly, you might cause user connectivity issues, as the cluster might drop transactions. Check your load balancer guide for details on how to configure this functionality.
SSL termination
If users access your application over HTTPS and your application is on a secure network, we recommend that you terminate SSL (or TLS) at the load balancer (or the reverse proxy if you are using one). SSL decryption and encryption is a CPU intensive process, and offloading this function to the load balancer ensures that the application node has more resources to handle its regular operations. This configuration also requires that you configure the load balancer to forward port 443 (HTTPS) to the HTTP port of your application. Check the product documentation for each application for the correct port number.

For additional information on load balancer configuration, including SSL termination requirements, see the following links:
- Configure load balancer for Confluence Data Center
- Hipchat Data Center network configuration requirements
- Configure load balancer for Bitbucket Data Center
High availability load balancers
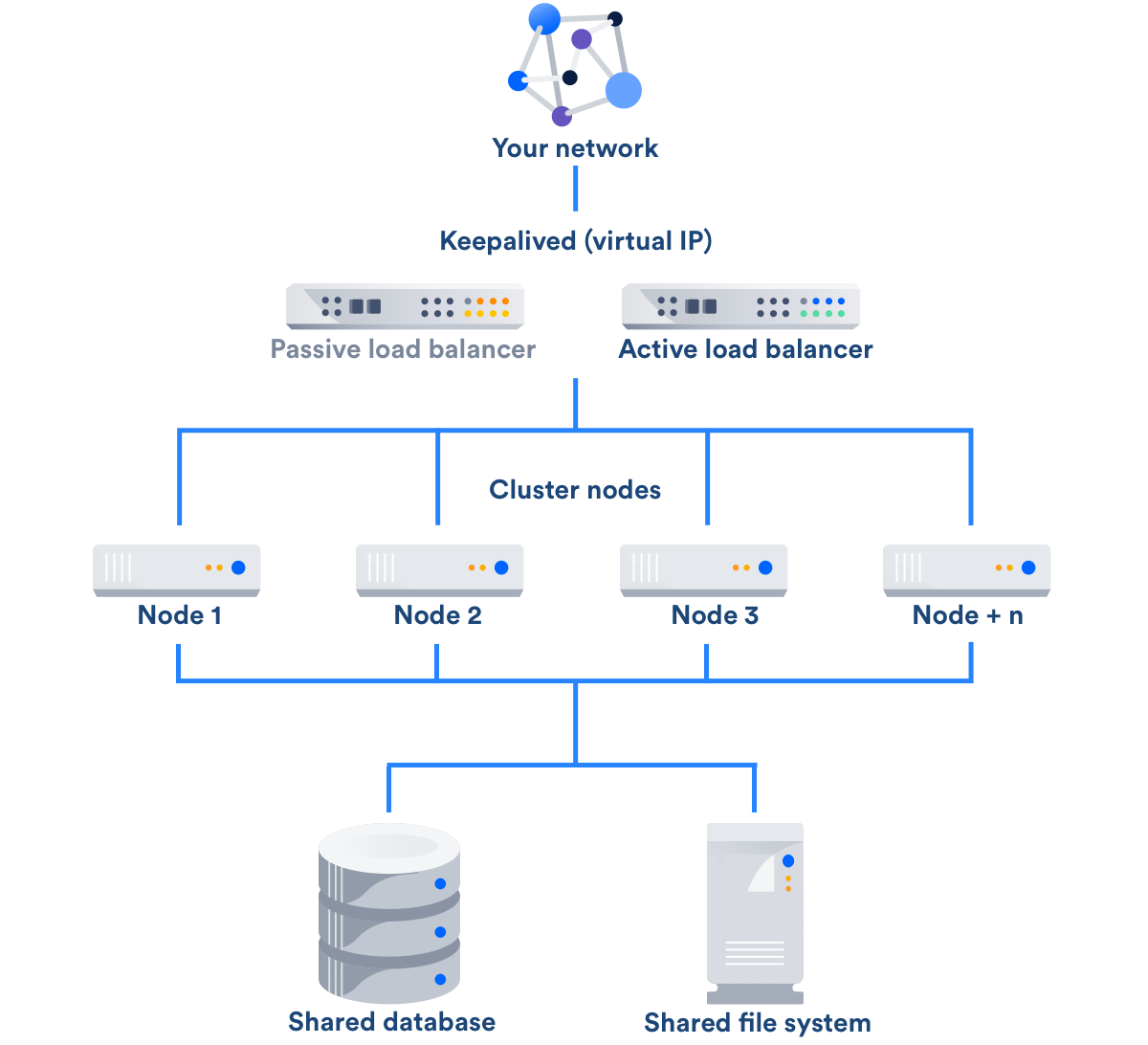
You can prevent the load balancer from becoming a single point of failure in your environment by adding redundancy to your load balancing solution. You can do this by setting up two load balancers in an active-passive configuration, using a virtual IP address across both load balancers. If the active load balancer fails, it will failover to the passive load balancer. Keepalived is a common tool used for creating a highly available load balancing solution.
For more information, review this HAProxy and Keepalived example configuration.
Comments
0 comments
Please sign in to leave a comment.